В издательстве «Манн, Иванов и Фербер» переиздана поэма «Демон» М.Ю. Лермонтова с предисловием сотрудника Лаборатории цифровых исследований литературы и фольклора Бориса Орехова. Текст предисловия доступен на сайте, в разделе статей публикаций сотрудников.


2 марта 2025
В библиографическом разделе Репозитория открытых данных по русской литературе и фольклору опубликован новый датасет «Роспись содержания советских толстых журналов, 1955—1990 (Новый Мир, Октябрь, Наш Современник, Звезда, Знамя, Юность)». В него вошли обширные сведения о литературных произведениях, напечатанных в главных советских толстых журналах.
Основная таблица содержит данные о названиях произведений, жанровые метки, данные об авторах и их партийной принадлежности. В двух дополнительных таблицах представлены данные о составах редакционных коллегий журналов и списках лауреатов литературных премий.
Датасет может использоваться не только как источник сводной библиографии толстых литературных журналов, но и как основа для исследований о путях распространения текстов и их канонизации с учетом институциональных факторов.

2024
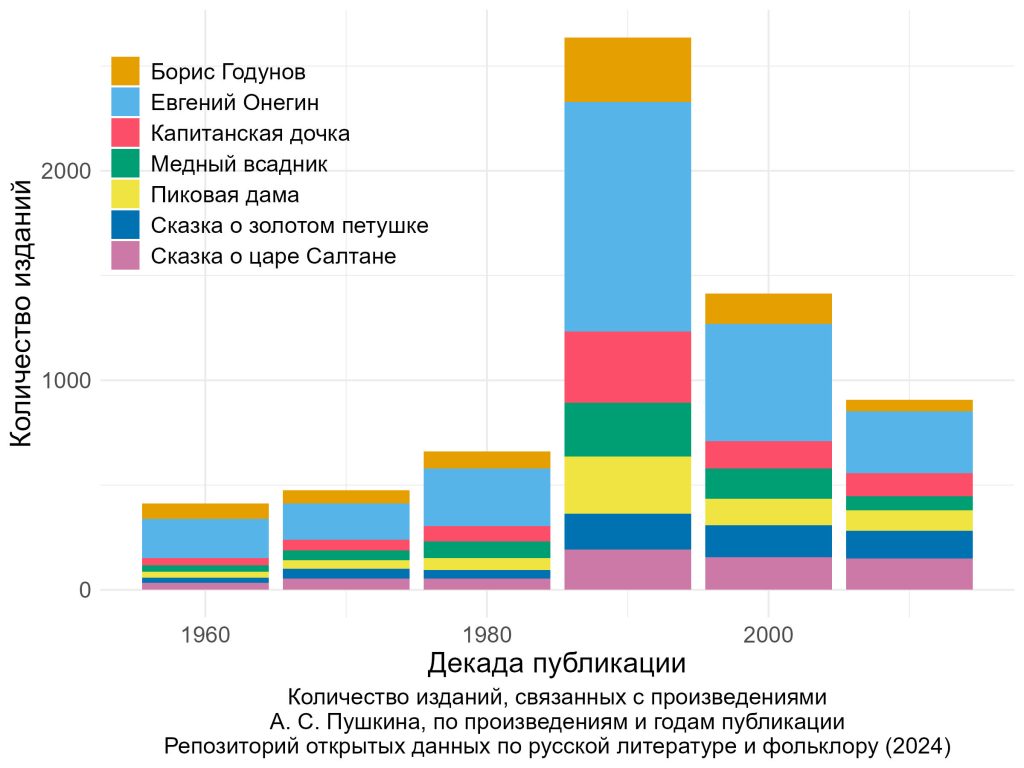
Опубликован новый датасет «Пушкиниана: библиография научных и критических работ, посвящённых А. С. Пушкину». Датасет создан на основе «Пушкинианы» — базы данных, в которой содержатся библиографические сведения об изданиях произведений А. С. Пушкина, их переводах, а также исследовательских материалах о них, биографии писателя и его творчестве. Данные «Пушкинианы» собраны сотрудниками Пушкинского кабинета ИРЛИ (Пушкинский Дом) РАН из различных источников.
Более 50 тыс. библиографических записей содержат сведения об оригинальных текстах Пушкина, справочных изданий по пушкинистике, библиографических указателях, сборниках материалов конференций, пристатейной библиографии и рецензиях. Записи снабжены уникальными идентификаторами UID, позволяющими определить, каким произведениям посвящено издание. Датасет позволяет работать с данными «Пушкинианы» удаленно, делая их более доступными и расширяя круг пользователей.
Опубликованы вторые версии датасетов «Индекс произведений и писем А. С. Пушкина» и «Корпус стихотворений А. С. Пушкина», дополненные сведениями 5-го тома Пушкинской энциклопедии.
Все три перечисленных датасета формируют цифровую репрезентацию стихотворных текстов, библиографии и метабиблиографии Пушкина и могут служить материалом в том числе для количественных исследований. Датасеты могут использоваться совместно, так как содержат объединяющие их идентификаторы произведений UID.
29 декабря 2023
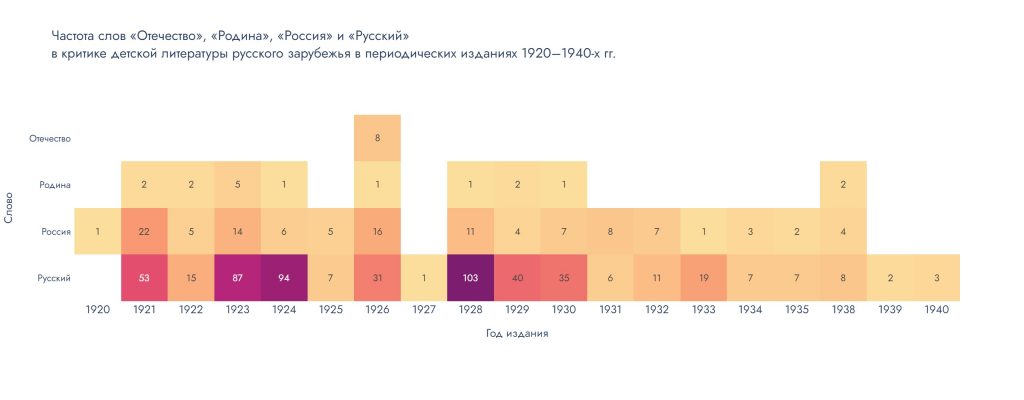
Опубликована новая версия (V2) датасета Анны Димяненко «Критика детской литературы русского зарубежья в периодических изданиях 1920–1940-х гг.»
Новая версия датасета помимо библиографических данных включает полные тексты 250-ти статей, рецензий и обзоров, посвященных книгам, изданным для детей на русском языке, детскому чтению, библиотекам и издательствам, выпускавшим литературу для детей за рубежом. Материалы отобраны из периодических изданий, выходивших в Европе с 1920 по 1940 гг. на русском языке. В библиографические данные внесен ряд уточнений и корректировок.
Данные пополнили корпус Деткорпус.Критика, интерфейс которого позволяет осуществлять комплексный поиск по текстам. Для удобства пользователей тексты эмигрантской печати объединены в отдельный подкорпус.
28 декабря 2023
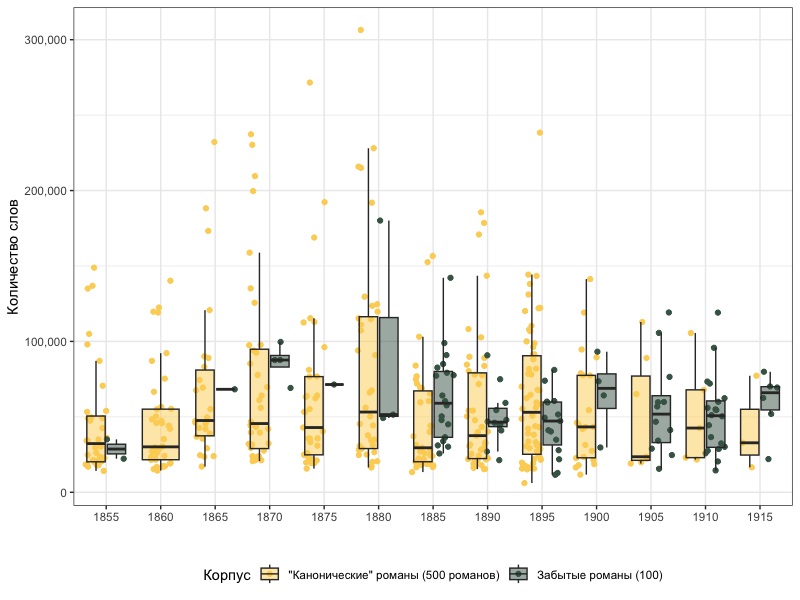
Раздел Корпуса текстов Репозитория пополнился датасетом «Забытые романы русских писателей из фондов Пушкинского Дома (1857–1917)». Датасет состоит из 100 текстов романов малоизвестных русских писателей, хранящихся в фондах Института русской литературы РАН (Пушкинского Дома). Оцифрованные копии текстов автоматически распознаны и снабжены метаданными, в числе которых сведения о раскрытых псевдонимах, библиографическая информация об оцифрованном издании, а также дата первой публикации произведения.
Эта публикация вводит в научный оборот произведения из малодоступных изданий, которые почти наверняка никогда ранее не были оцифрованы. Такой материал позволит исследователям сформировать более объемное представление как о жанровых особенностях романа, так и в целом о литературе второго ряда, изданной во второй половине XIX — начале XX вв.
Вместе с «Корпусом нарративной прозы XIX в.», коллекция «забытых романов» представляет значительный срез крупных прозаических произведений XIX в. на русском языке.
6 декабря 2023
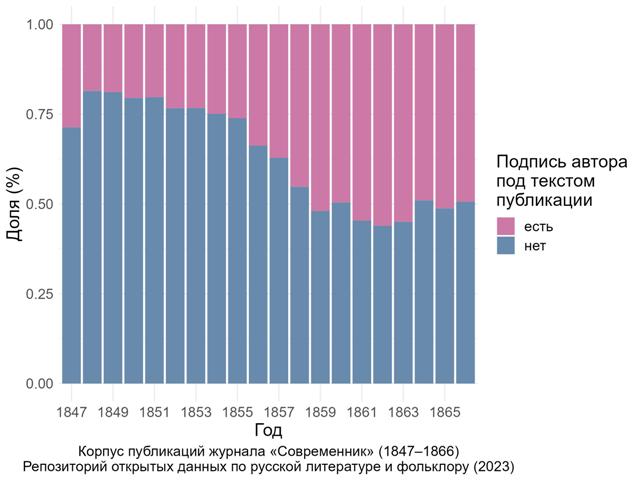
Корпусный раздел Репозитория пополнился датасетом Екатерины Вожик «Корпус публикаций журнала «Современник» (1847–1866)».
Этот корпус открывает более широкие возможности для систематических цифровых и количественных исследований по материалам одного самых известных литературных журналов России. Датасет включает автоматически распознанные тексты 4686 публикаций основного содержания «Современника» и расширенные метаданные к ним. Структура таблицы метаданных задана сведениями основного авторитетного источника – указателя В. Э. Бограда (Боград В. Э. Журнал «Современник». 1847–1866: Указатель содержания. М.; Л.: ГИХЛ, 1959), которые были уточнены, реструктурированы и дополнены составительницей датасета. В частности, восстановлены опущенные Боградом указания на авторов в заглавиях статей. Данные сверены de visu по оригинальным выпускам журнала, включая пятый выпуск за 1866 г., часть тиража которого была изъята цензурой. Набор метаданных включает не только базовую информацию о публикации и ее авторе, но и сведения о датах фактического выхода журнала в свет и датах цензурных разрешений, принадлежности к определенному разделу журнала, адресатах посвящений и др. В отдельной таблице приведены метаданные к журнальным приложениям «Современника».
28 ноября 2023
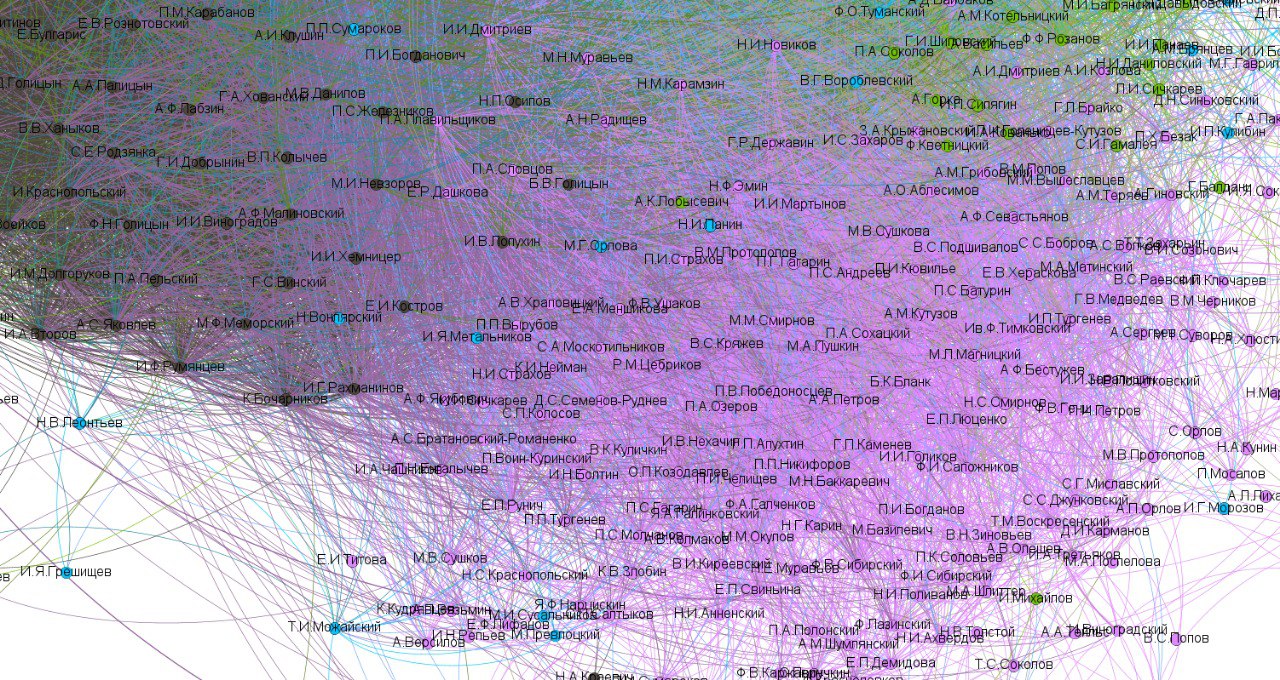
Раздел Репозитория Биографические данные пополнился датасетом Рината Бакирова и Бориса Орехова «Русско-европейские литературные связи XVIII векаx».
Датасет представляет собой сведения о литературных контактах русских и европейских писателей по данным двух справочных изданий — «Словаря русских писателей XVIII века» и энциклопедического словаря «Русско-европейские литературные связи — XVIII век». Упоминания писателей выделены из словарных статей и приведены в табличную машиночитаемую форму. Эти данные также агрегированы в файл, готовый к загрузке в программу сетевого анализа.
Датасет будет полезен при составлении наиболее полной картины связей писателей в русской литературе XVIII века, которая позволит наблюдать литературные и экстралитературные процессы в динамике, в том числе, с учетом литературных направлений, стилей, групп. Кроме того, датасет связан с датасетом Словарь русских писателей XVIII века: сеть персоналий за счет унифицированного обозначения персоналий, что позволяет использовать их совместно.
24 ноября 2023
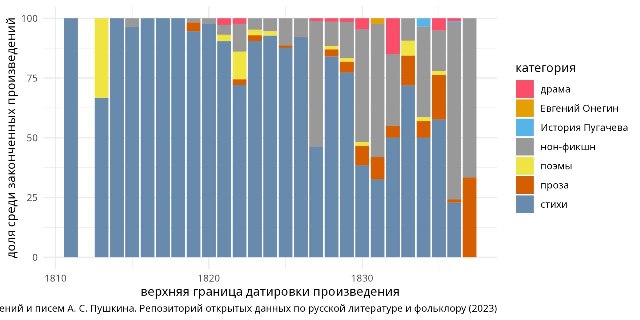
Датасет «Индекс произведений и писем А. С. Пушкина», опубликованный в библиографическом разделе Репозитория, представляет собой сводный перечень, систематизирующий имеющиеся в распоряжении современной пушкинистики сведения о письменном наследии поэта.
Своей главной целью авторы датасета видели составление списка произведений, объединяющего все письменное наследие Пушкина, и присвоение каждому произведению уникального идентификатора (UID), позволяющего однозначно его определить. Датасет включает в себя три таблицы: oeuvre, letters и texts, — представляющие сведения о художественных и нехудожественных произведениях Пушкина, его письмах и текстах, которые написаны его рукой (выписки и записи разного содержания, официальные документы).
В основе датасета лежат переведенные в табличную форму данные «Пушкинской энциклопедии», работа над которой ведется в Институте русской литературы (Пушкинский Дом) Российской Академии наук с 2009 года. Сведения о письмах и текстах, написанных «рукою Пушкина», актуализированы в сотрудничестве с Отделом пушкиноведения и Рукописным отделом ИРЛИ РАН.
22 июня 2023
Новый датасет: Литературные произведения в государственных стандартах и программах для средней школы 1998–2022 гг.
Раздел Репозитория Библиографические данные пополнился датасетом Андрея Кокорина «Литературные произведения в государственных стандартах и программах для средней школы 1998—2022 гг.»
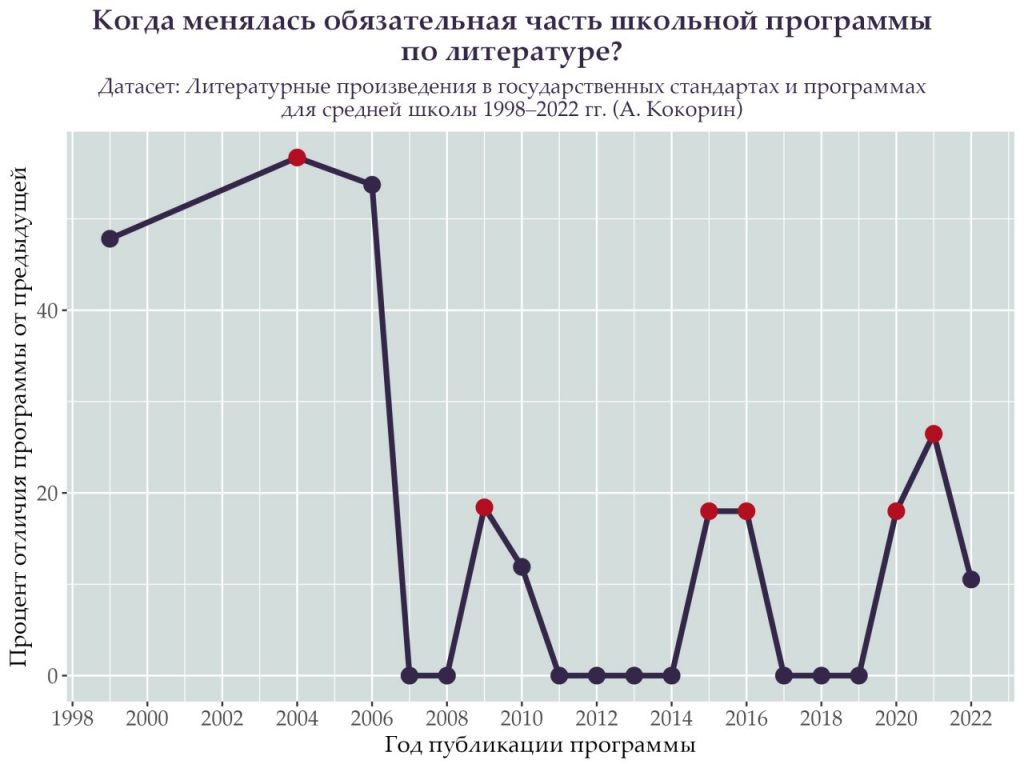
Датасет представляет собой роспись литературных произведений, вошедших в постсоветские государственные стандарты и программы средней школы по родной литературе, а также в кодификаторы основного и единого государственных экзаменов по литературе — то есть все официальные документы, регламентирующие школьное преподавание русской литературы.
Произведения в таблице снабжены расширенными метаданными: помимо базовых (автор, время создания, жанр) приводятся сведения об обязательности изучения автора и произведения, наличие рекомендации к углубленному изучению, сведения о возможности выбора текстов учащимися.
Вместе с уже опубликованными в Репозитории датасетами Хрестоматии Российской Империи с 1805 по 1912 гг. и Программы по литературе для средней школы с 1919 по 1991 гг. эта публикация формирует цикл, позволяющий изучать становление и трансформацию школьного литературного канона на хронологическом отрезке более чем в 200 лет.
12 апреля 2023
Доклад-презентация Кирилла Александровича Маслинского «Открытые данные в филологических науках: опыт Репозитория открытых данных ИРЛИ и возможности публикации древнерусских материалов».
20 марта 2023
Лаборатория цифровых исследований русской литературы представляет вашему вниманию два веб-приложения с визуализацией данных: Таймлайн жизни русских писателей и Персоналии в Словаре русских писателей XVIII века.
17 февраля 2023
Новый датасет: Бытование литературных текстов в ГУЛАГе
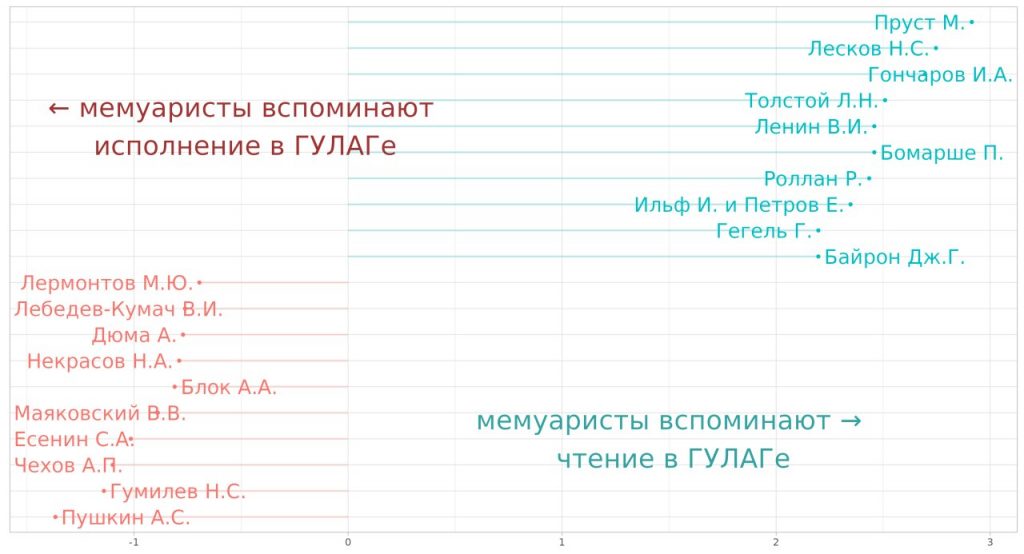
В разделе Библиографические данные Репозитория опубликован новый датасет Бытование литературных текстов в ГУЛАГе.
Группа исследователей НИУ «Высшая школа экономики» обработала крупный общедоступный корпус мемуаров и извлекла из него упоминания литературных произведений, бытовавших в советской пенитенциарной системе в 1917—1991 гг. Каждое упоминание снабжено метаданными: когда, кем, где и при каких обстоятельствах осуществлялась рецитация текста. Широкие хронологические рамки, большой объем вхождений (более 2500 единиц) и подробные метаданные делают этот датасет чрезвычайно интересным и удобным для всего спектра гуманитарных исследований. Наряду с датасетом Программы по литературе для средней школы с 1919 по 1991 гг. эти данные могут служить материалом для изучения процесса трансформации литературного канона в советскую эпоху.
Данные сопровождаются описанием на русском и английском языках.
Новый датасет: Авторы и произведения для детского чтения в критике 1860—1880-х гг.
Раздел репозитория Библиографические данные пополнился датасетом Ольги Лучкиной «Авторы и произведения для детского чтения в критике 1860—1880-х гг.».
Данные представляют собой роспись изданий (фамилии литераторов и названия произведений), упомянутых в критических и педагогических статьях, обзорах, рецензиях и списках, опубликованных на страницах «Журнала Министерства народного просвещения», «Педагогического сборника», «Женского образования» в 1860—1880-х гг. Эти журналы, издаваемые или контролируемые правительственными ведомствами, стали новыми площадками для публичного обсуждения детской литературы, а рекомендательная практика — одним из ранних этапов формирования литературного канона.
Результаты анализа данных представлены в диссертации автора «Формирование канона литературы для детей в критике 1860—1880-х гг.».
2022 год
26.12.2022
Новый датасет: Критика детской литературы русского зарубежья в периодических изданиях 1920–1940-х гг.
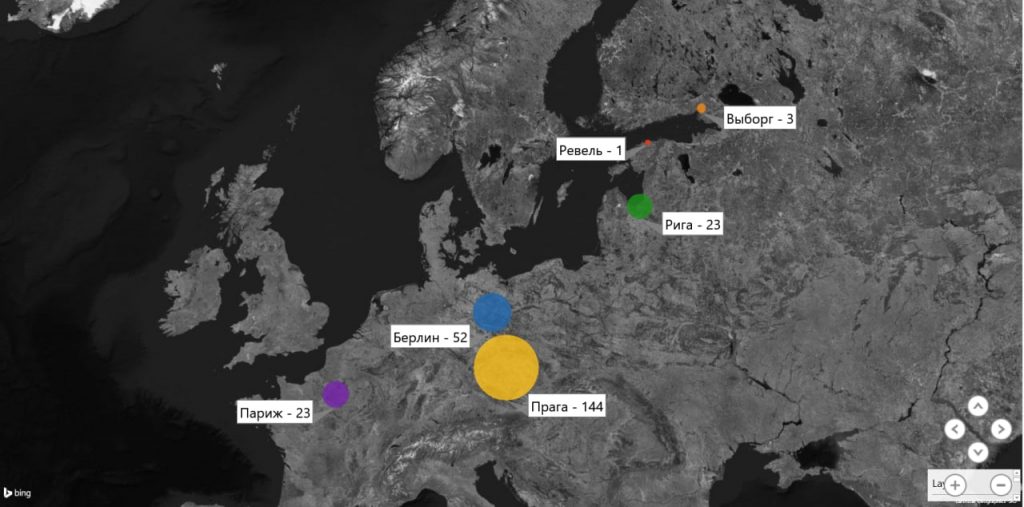
В Репозитории открытых данных опубликован новый датасет — Критика детской литературы русского зарубежья в периодических изданиях 1920–1940-х гг. Данные представляют собой библиографические сведения о 246 рецензиях и критических статьях о литературе для детей и детском чтении. Материалы отобраны из периодических изданий, выходивших в Европе с 1920 по 1940 гг. на русском языке. Критические статьи выявлены как в известных, многотиражных изданиях, распространяющихся по подписке по всем странам, так и в локальных изданиях, отпечатанных на ротаторе. Данные позволяют составить картину территориального распределения центров изучения детской литературы, выявить ядро изданий, вовлеченных в обсуждение проблематики, и ключевых авторов.
В комплексе с датасетом Детская книга русского зарубежья в Европе 1919-1954 гг. эта публикация позволяет создать более объемное представление о литературном процессе русского зарубежья.
14.12.2022
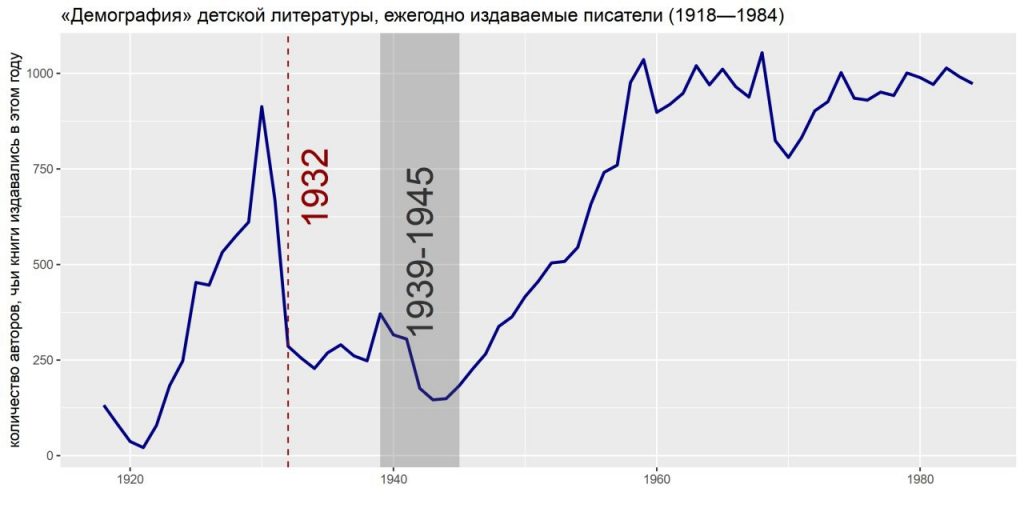
Новый датасет: Библиография детской книги 1918–1984.
В Репозитории открытых данных опубликован новый датасет — Библиография детской книги 1918–1984. Датасет представляет собой библиографическую базу данных по русской детской книге XX века, приведенную в машиночитаемый табличный формат для удобства поиска и статистического анализа. База основана на 18-томном библиографическом указателе «Детская литература», составленном И. И. Старцевым и его продолжателями. В библиографию включались все книжные издания за 1918–1984 гг. на русском языке, выходившие в СССР и адресованные детям и юношеству. Для удобства обработки и анализа данных библиографические записи из указателей были разделены на отдельные поля (автор, заглавие, место издания, издательство, год, тираж и т.д.) с помощью автоматического анализатора.
12.12.2022
Новый датасет: Программы по литературе для средней школы с 1919 по 1991 гг.
В Репозитории открытых данных опубликован новый датасет Программы по литературе для средней школы с 1919 по 1991 гг.. Датасет представляет собой роспись произведений фольклора, русской и зарубежной литературы, вошедших в 50 школьных программ советского периода. Помимо основных метаданных (автора, источника, даты) в таблицу включены сведения о рекомендациях составителей по изучению произведений (чтение отдельных глав или отрывков, возможность выбора преподавателем и учащимися) и степени их приоритетности в программе. Хотя данные имеют ряд ограничений, они позволяют делать наблюдения относительно подходов к изучению литературы в советской школе, формировании литературного канона, роли и месте отдельных произведений. Публикация может рассматриваться как продолжение цикла данных по составу школьного литературного канона, открытого публикацией датасета Хрестоматии Российской Империи с 1805 по 1912 гг.

26.10.2022
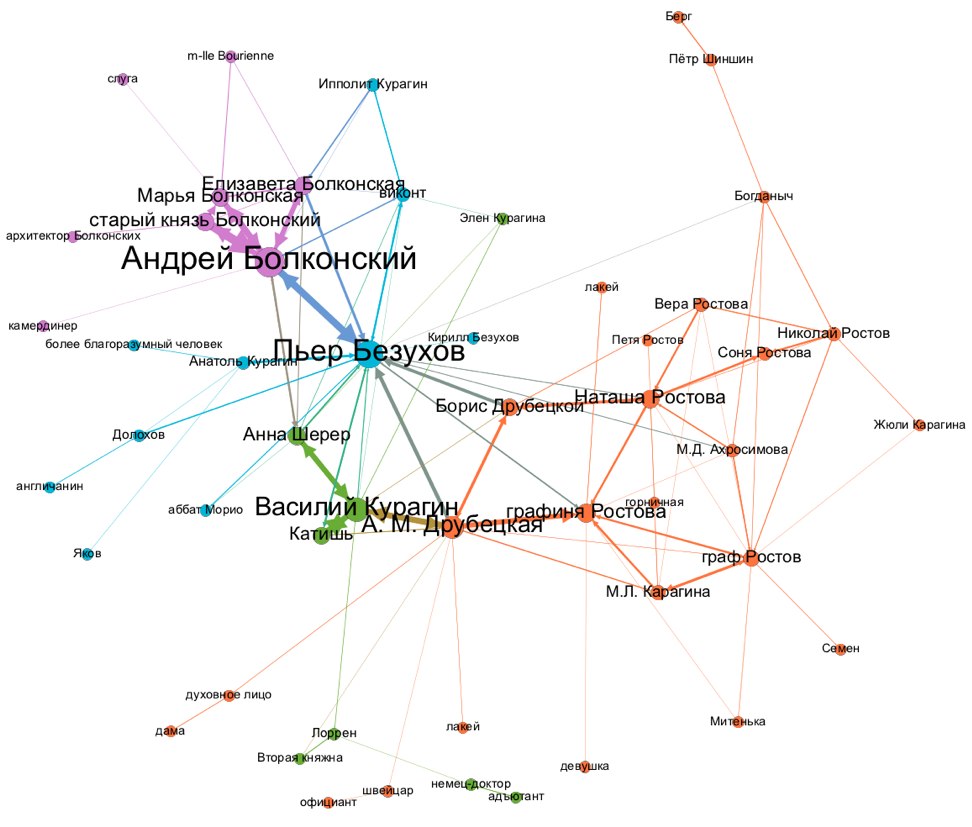
Новый датасет: «Персонажи «Войны и мира» Л. Н. Толстого: вхождения в тексте, прямая речь и семантические роли»
В разделе Корпуса текстов Репозитория открытых данных по русской литературе и фольклору опубликован новый датасет Персонажи «Войны и мира» Л. Н. Толстого: вхождения в тексте, прямая речь и семантические роли. Данные представляют собой полный текст романа, размеченный в соответствии со стандартом TEI.
Автор датасета Даниил Скоринкин выполнил разметку, указывающую на упоминания персонажей, их прямую речь и семантические роли. Всем основным персонажам романа присвоены уникальные идентификаторы, они же связаны с текстами реплик прямой речи этих персонажей и их адресатами. Разметка семантических ролей указывает на те случаи, когда персонаж совершает действие, становится объектом действия или переживает какой-то чувственный или мыслительный опыт.
Эти данные позволят выполнять существенно более глубокие исследования системы взаимодействия персонажей в тексте и выявлять ее неявные особенности. Некоторые научные результаты отражены в диссертации автора датасета, а кроме того, в онлайн-лекции Даниила Скоринкина «Сетевой анализ художественной литературы» (обсуждение сети персонажей Войны и мира там начинается с позиции 1:05:05).
07.10.2022
Новый датасет: «Данные для воспроизведения исследования: Лекаревич, Е. Домашние дела литературных персонажей»
В Репозитории открытых данных по русской литературе и фольклору опубликован новый датасет в разделе Воспроизводимые данные, позволяющий воспроизвести результаты исследования Евгении Лекаревич «Домашние дела литературных персонажей», опубликованного в журнале «Детские чтения» 20(2):155-74.
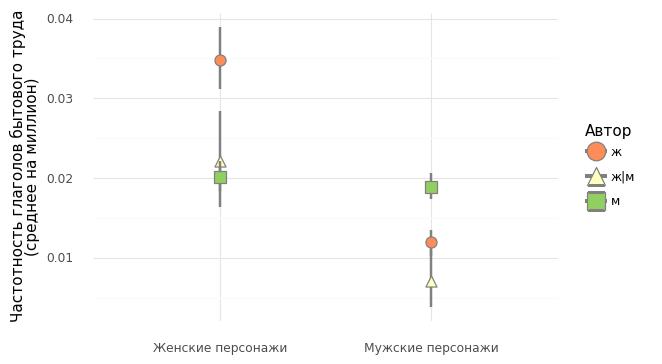
В работе проанализирована частотность изображения персонажей-женщин и мужчин, занятых бытовым трудом, в русской детской литературе XX-XXI вв. — на материале Корпуса русской литературы для детей и юношества (Деткорпус). Количественные выводы сделаны на основании анализа контекстов употребления глаголов, обозначающих бытовой труд.
В советской и постсоветской детской литературе так же, как и в литературе для взрослых, у авторов-мужчин значительно преобладают персонажи мужского пола, в то время как для авторов-женщин характерно несколько более эгалитарное распределение персонажей. Женские персонажи чаще изображаются за определенными видами бытовой работы авторами обоего пола. В статье с помощью тематического моделирования (LDA) выявлен круг романтических и приключенческих топосов, в рамках которых изображаются мужчины и мальчики, занятые обустройством быта.
15.09.2022
Опубликована новая версия (2.0) датасета: Лучшие образцы русской литературы (1849–1900): антологии избранной поэзии и прозы, литературные сборники и альманахи, сборники для легкого чтения, антологии для народа, антологии для женщин.
В новой версии базы данных значительно расширен временной диапазон вошедших в нее антологий и сборников второй половины XIX в., что делает ее репрезентативным датасетом русских литературных антологий, альманахов и сборников избранной русскоязычной поэзии и прозы. Прежняя версия датасета была ограничена 1869 годом, новая же версия включает в себя литературные сборники, альманахи и антологии 1870-1900 гг., а также датасет дополнен несколькими прежде не вошедшими в его состав изданиями 1849-1869 гг.
28.06.2022
Новый датасет: «Корпус русской литературной баллады 1840 гг.»
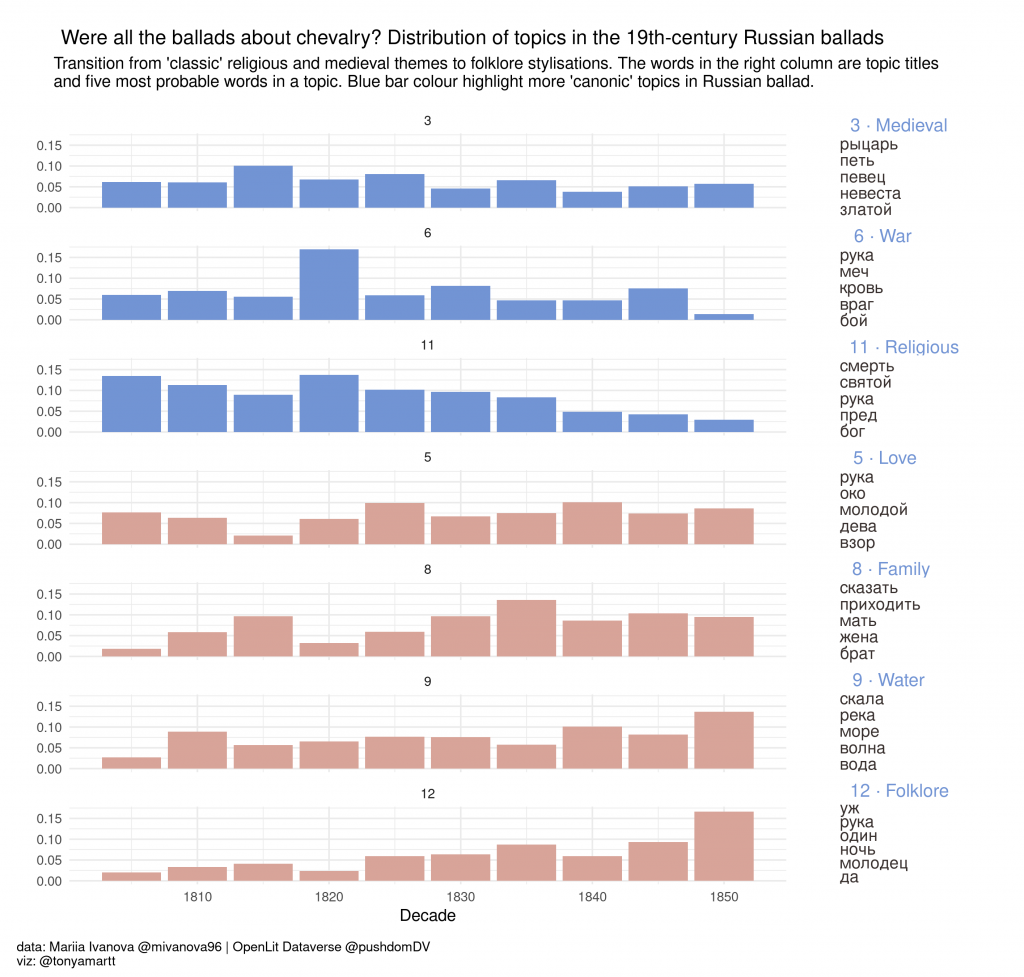
В Репозитории открытых данных по русской литературе и фольклору опубликован новый датасет — Корпус русской литературной баллады 1840-х гг., собранный Марией Ивановой.
В корпус вошло 212 текстов, опубликованных в периодических изданиях и сборниках 1840-х гг. под заголовком «Баллада» или в одноименном разделе; также включались тексты, обладающие характерными балладными признаками, сформулированными в исследовательской традиции: к ним относятся наличие фабулы и сюжетная основа, взятая из фольклора, средневековой литературы, античной мифологии и, реже, обыденной жизни, а также элемент чудесного (см. исследования Р. В. Иезуитовой и О. А. Левченко).
Тексты снабжены подробными метаданными, включающими как стиховые характеристики (метр и размер, строфическая формула и т.д.), так и специфические для баллады признаки (тип повествования, указание на переводную природу текста). В библиографическом отношении метаданные корпуса позволяют исследовать степень распространения балладного жанра в авторских сборниках и периодике 1840-х гг.
В сравнении с корпусом «канонической» баллады начала XIX в., представленной балладами В. А. Жуковского, П. А. Катенина, А. С. Пушкина и М. Ю. Лермонтова, корпус баллад 1840-х гг. представляет базу для изучения развития жанра и механизмов его трансформации на исходе «золотого века» русской поэзии. О нескольких находках в этом направлении см. работу Марии «Жанр литературной баллады в 1840-е годы» (Тарту, 2022).
13.04.2022
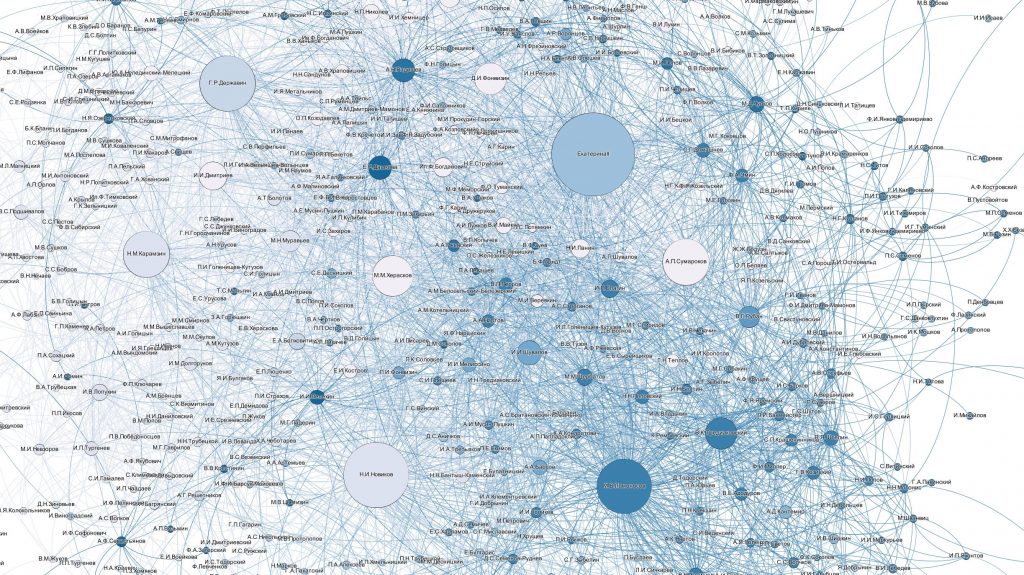
Новый датасет: «Словарь русских писателей XVIII века: сеть персоналий»
В Репозитории открытых данных по русской литературе и фольклору опубликован новый датасет — сеть персоналий, построенная на основании междустатейных ссылок в «Словаре русских писателей XVIII века» (1988—2010. Вып. 1—3). Узлами сети выступают посвященные персоналиям статьи словаря, а ребрами — ссылки на другие статьи в том же словаре. Такая сеть позволяет проследить ключевые тенденции в социальном и интеллектуальном взаимодействии литераторов XVIII века. Данные без предварительной обработки можно загружать в программы для сетевого анализа при решении учебных задач.
Более внимательно рассмотреть сетевые связи литераторов из этого датасета можно с помощью интерактивного веб-приложения, построенного на данных этого датасета. Приложение позволяет работать с отдельными узлами сети, изучать их соседей и количественные характеристики.
08.04.2022
Обновление датасета: Корпус русской прозы для детей и юношества
Опубликована новая версия (2.0) датасета «Корпус русской прозы для детей и юношества». В новой версии пополнен подкорпус художественной литературы, преимущественно текстами 1920-х гг. Сборники повестей и рассказов были разобраны на отдельные произведения. Общий объем корпуса к настоящему моменту — 2703 произведения. Полнотекстовый поиск по новой версии корпуса доступен на сайте detcorpus.ru.
16.02.2022
Руководитель лаборатории цифровых исследований Кирилл Маслинский выступил с докладом «О культуре работы с данными в DH, или роль Репозитория открытых данных» на семинаре «Цифровая среда» Сибирского федерального университета.
Запись семинара доступна по ссылке https://www.youtube.com/watch?v=18BUQBh2P5E&ab_channel=DigitalHumanitiesResearchInstitute
2021 год
24.12.2021
Новый датасет: Хрестоматии Российской империи (1805—1912)
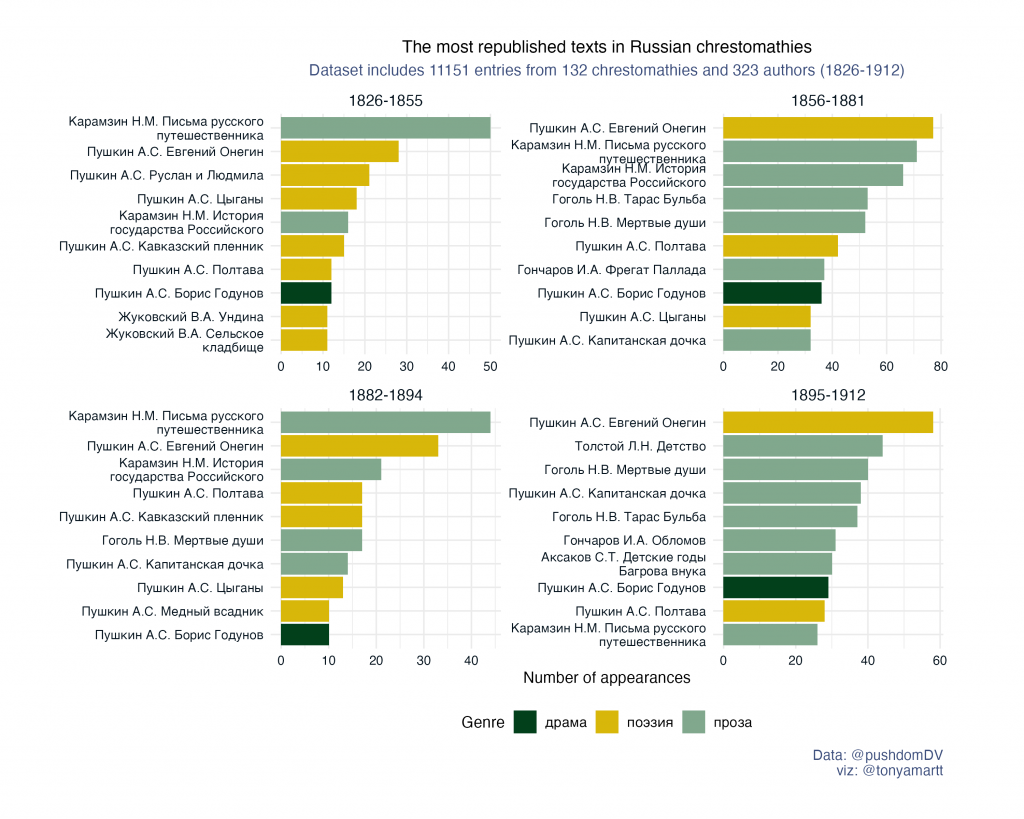 В Репозитории открытых данных по русской литературе и фольклору опубликован новый датасет — Хрестоматии Российской Империи с 1805 по 1912 гг. Данные представляют собой перечень литературных произведений и отрывков из них, напечатанных в русскоязычных хрестоматиях, выходивших на территории Российской Империи в указанный период. Авторы датасета Роман Лейбов и Алексей Вдовин работали с хрестоматиями de visu в библиотеках Санкт-Петербурга, Москвы, Таллина, Тарту, Елена Казакова откорректировала и подготовила данные к публикации.
В Репозитории открытых данных по русской литературе и фольклору опубликован новый датасет — Хрестоматии Российской Империи с 1805 по 1912 гг. Данные представляют собой перечень литературных произведений и отрывков из них, напечатанных в русскоязычных хрестоматиях, выходивших на территории Российской Империи в указанный период. Авторы датасета Роман Лейбов и Алексей Вдовин работали с хрестоматиями de visu в библиотеках Санкт-Петербурга, Москвы, Таллина, Тарту, Елена Казакова откорректировала и подготовила данные к публикации.
Всего в базе содержится 11294 записи, имена авторов и произведений нормализованы в соответствии с формами, принятыми в современном литературоведении. Единицей вхождения является полное произведение или отрывок из него, при наличии сведений указаны границы отрывка, адресация хрестоматий, особенности публикации текстов. Дополнительно приведены полные библиографические описания источников.
Список хрестоматий не исчерпывает абсолютно всех изданий подобного типа, вышедших на территории империи за указанный период времени, поскольку охватывает преимущественно хрестоматии для среднего и старшего звена гимназий и реальных училищ. Пособия для начальной школы представлены в базе в очень ограниченном числе, так как художественные произведения в них использовались в первую очередь для обучения языку и грамматике, а не для историко-литературного разбора. По оценкам авторов, в датасете учтены 70—75% хрестоматий для средних классов и 10-15% хрестоматий для начальной школы.
11.11.2021
Важные новости — теперь ДетКорпус доступен исследователям не только для онлайн-поиска, но и в качестве датасета (https://dataverse.pushdom.ru/dataset.xhtml?persistentId=doi:10.31860/openlit-2021.4-C001), опубликованного в Репозитории открытых данных по литературе и фольклору. Формат и набор данных, включенных в датасет, подобран таким образом, чтобы на этом материале можно было воспроизвести статистические расчеты, сделанные на исходных текстах корпуса, а также проводить новые количественные исследования, опирающиеся на грамматическую и лексическую статистику. Подробное описание состава датасета (2273 прозаических произведения, опубликованных на русском языке в период с 1900-х по 2020-е годы) можно найти в файле README датасета и на сайте http://detcorpus.ru/.
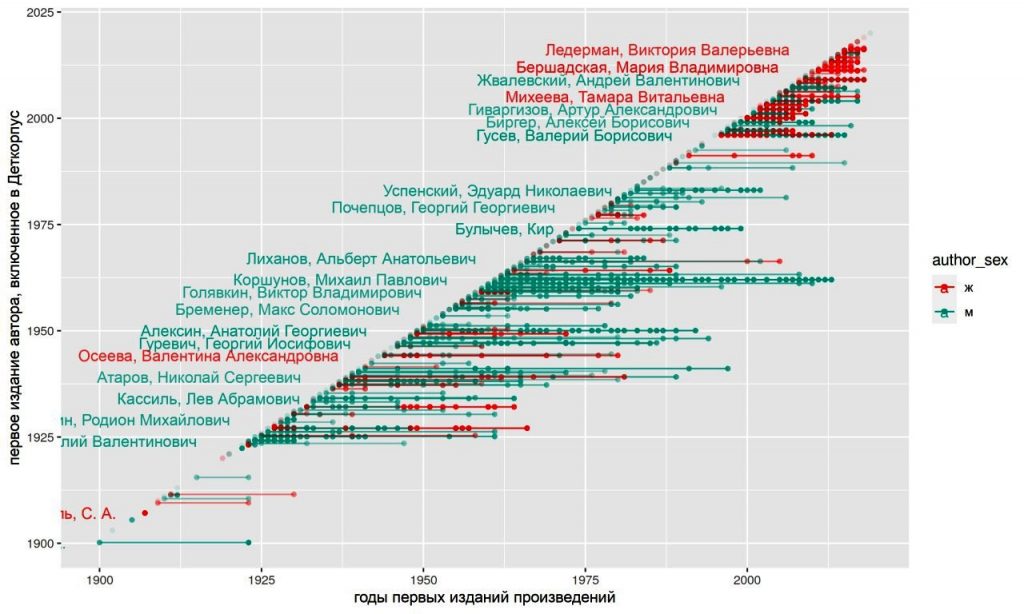
Кроме технического обновления, есть и содержательное — новый выпуск Деткорпуса включает в себя более ста произведений 1920-х годов. Тексты предоставлены Российской государственной детской библиотекой и подготовлены к публикации: вычитаны и сверены с оригиналами. Благодаря сотрудничеству с РГДБ мы и дальше сможем пополнять Деткорпус произведениями начала XX века, расширяя ретроспективный охват нашей выборки. Среди ранних текстов стоит отдельно отметить подкорпус нон-фикшн 1920-х, в который вошли научно-популярные издания по естественным наукам, а также технике и технологиям. Интерфейс Деткорпуса позволяет познакомиться с фрагментами этих произведений, а иллюстрированные цифровые копии доступны для читателей в НЭДБ.
Лаборатория цифровых исследований литературы и фольклора и Центр исследований детской литературы тепло благодарят РГДБ и лично Илью Гавришина, благодаря которому это обновление стало возможным. За помощь с подготовкой текстов к публикации мы признательны главному библиографу ЛОДБ Любови Алейник, а также студенткам филологической программы НИУ ВШЭ СПб Злате Климас, Екатерине Стариковой и Анне Логиновой.
30.01.2021
Обновление Корпуса Детской литературы: русскоязычный интерфейс, пополнение коллекции и обновленные метаданные.
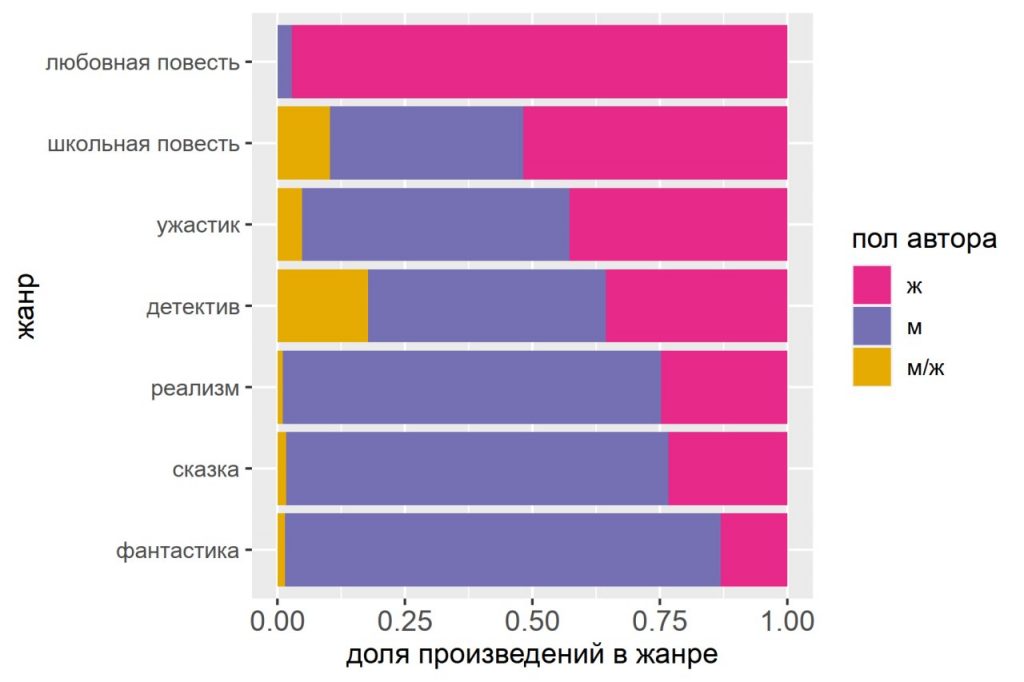
Новый релиз Деткорпуса содержит существенные обновления сразу в нескольких направлениях. Изменилась структура: теперь познавательная (нон-фикшн) и художественная литература для детей представляют собой два разных корпуса, переключаться между коллекциями текстов можно со страницы выбора корпуса: http://detcorpus.ru/search/#open
Интерфейс корпуса переведен на русский язык — пользователям стали доступны всплывающие подсказки, поясняющие работу корпусных инструментов, а также развернутые инструкции по работе с базовыми функциями интерфейса.
Существенная часть текстов дополнена метаданными, проаннотировано более 1000 текстов. Упорядочен вывод метаданных в корпусном интерфейсе, стали доступны краткие библиографические описания книжных изданий. Сейчас в корпусе все произведения сопровождаются как минимум базовым набором метаданных: автор, год издания корпусной копии и/или первого издания, выходные данные, — что одновременно упрощает атрибуцию цитат и расширяет возможности для количественного анализа.
Корпус пополнился несколькими сотнями произведений 1960-х—1980-х гг., а также несколькими десятками текстов 1920-х—1930-х. Добавлен подкорпус фантастики 1930-х—1960-х, выборка составлена на основе указателя «Детская литература» за 1946—1966 гг., к настоящему моменту этот подкорпус составляет 178 произведений. В корпусе появилась новая жанровая метка — biography, по ней можно отобрать беллетризированные биографии для детей.
Объем корпуса к настоящему моменту — 1991 произведение.
2020 год
08.12.2020
В Репозитории открытых данных по русской литературе и фольклору опубликован новый датасет — Корпус нарративной прозы XIX в. Подробнее
10.11.2020
В Репозитории открытых данных по русской литературе и фольклору опубликован новый датасет — библиографические сведения о 602 детских книгах, изданных в Европе русскими эмигрантами первой волны с 1919 по 1954 гг. Данные собраны Анной Димяненко в процессе написания диссертации на соискание степени кандидата филологических наук «Детская книга русского зарубежья в Европе, 1920-1956-е гг.» и ранее полностью нигде не публиковались. Датасет подготовлен для автоматизированного анализа: нормализованы написания дат, авторов, городов издания, приведены географические координаты городов.
Этой публикацией мы открываем раздел Библиографических данных в Репозитории.
13.10.2020
В Репозитории открытых данных по русской литературе и фольклору опубликован новый датасет — сведения о встречах Ходасевича со знакомыми в эмиграции (1922—1939), которые он фиксировал в своем «Камер-фурьерском журнале». Данные подготовлены Борисом Ореховым, Павлом Успенским и Вероникой Файнберг для биографического исследования, опубликованного в «Русской литературе» (2018, № 3). Датасет ориентирован не только на исследовательское, но и на учебное применение: помимо исходных данных в табличном виде (journal.tsv) в датасет включены файлы сетевых данных, которые можно непосредственно загружать и визуализировать в Gephi.
Этой публикацией мы открываем раздел Биографических данных в Репозитории.
16.09.2020
Мы рады объявить об открытии нового раздела в Репозитории открытых данных по литературе и фольклору — Данные для воспроизводимых исследований. Раздел открывается публикацией датасета Бориса Орехова Стилеметрические данные «Тихого Дона» и современной ему прозы. Эти данные относятся к исследованию автора датасета (в соавторстве с Н. П. Великановой), в котором на основании стилеметрических показателей установлено, что «Тихий Дон» написан тем же автором, что и «Донские рассказы». Датасет позволяет более внимательно рассмотреть все количественные показатели и воспроизвести расчеты.
Открытием этого раздела и публикацией данных в нем мы (редакция Репозитория) надеемся внести свой скромный вклад в укрепление высоких стандартов доказательности и воспроизводимости и лучших практик публикации открытых данных в литературоведении. Вопросы и предложения относительно публикации данных в репозитории просим направлять Кириллу Александровичу Маслинскому.
18.05.2020
Лаборатория цифровых исследований литературы и фольклора ИРЛИ объявляет об открытии Репозитория открытых данных по русской литературе и фольклору.
Репозиторий — это ресурс для хранения и публикации научных данных, которые авторы предоставляют в свободный доступ другим исследователям. В нашем случае это корпуса оцифрованных литературных текстов и библиографические базы данных. Публикация открытых данных в машиночитаемых форматах расширяет возможности цифровых и количественных исследований литературы, делает более доступной кропотливо собранную справочную информацию. Что немаловажно, те же данные могут послужить удобным материалом для студенческих проектов в области digital humanities.
Задачи репозитория — повысить видимость и доступность данных и поддерживать культуру цитирования данных. Все публикуемые датасеты проходят рецензирование и техническую подготовку для того, чтобы обеспечить достоверность, полноту и консистентность данных и получают DOI.
Приглашаем к сотрудничеству исследователей и образовательные программы. По всем вопросам пишите заведующему лабораторией Кириллу Александровичу Маслинскому.
12.04.2020
Коллеги, анонсируем пополнение Деткорпуса и обновление его интерфейса. В корпусе теперь 1726 произведений, и появились новые инструменты работы с ними. Приглашаем изучать отечественную детскую литературу!
2019 год
20.06.2019
Алексей Владимирович Вдовин, доцент департамента истории и теории литературы ВШЭ выступил с докладом
Корпус «Русский роман XIX века»: источниковая база и принципы ее отбора.
В докладе пойдет речь о первых результатах проекта преподавателей и студентов департамента истории и теории литературы и центра Digital Humanities («Высшей школы экономики», Москва), занятых созданием первого электронного корпуса текстов русских романов XIX столетия. Первым этапом проекта стало создание базы данных, в которой содержатся библиографические сведения о 1500 романах. Докладчик расскажет о том, из каких библиографических и других источников формировалась база, по каким принципам отбирались и представлялись тексты, какой процент из них уже оцифрован и может быть интегрирован в корпус. База данных уже позволяет получать первичные сведения о динамике годового числа новых романов на протяжении 19 века, эволюции заглавий, местах первой публикации, типе повествования и проч.
13.05.2019
На семинаре выступила Екатерина Владимировна Рахилина,
доктор филологических наук, профессор, руководитель Школы лингвистики Факультета гуманитарных наук НИУ ВШЭ (Москва) с докладом «М. Ю. Лермонтов «Герой нашего времени». Лингвистическое чтение».
Не бросающиеся в глаза сдвиги в лексико-грамматической структуре современного русского языка по сравнению с языком первой трети XIX века теперь можно исследовать с помощью Национального корпуса русского языка. Один из разработчиков НКРЯ Екатерина Владимировна Рахилина расскажет об этих изменениях на примере прозы М. Ю. Лермонтова. В качестве классического, хрестоматийного текста «Герой нашего времени» многократно комментировался специалистами и считается одним из самых прозрачных и понятных современному читателю, хотя бы в отношении языка. Тем более интересно на материале этого романа рассмотреть «под микроскопом» те изменения, которые за два века претерпел современный русский язык, стремительно отдаляющийся от канона классики.
Видеозапись семинара на youtube канале Пушкинского Дома https://www.youtube.com/watch?v=ujnlRIWRSsM
22.04.2019
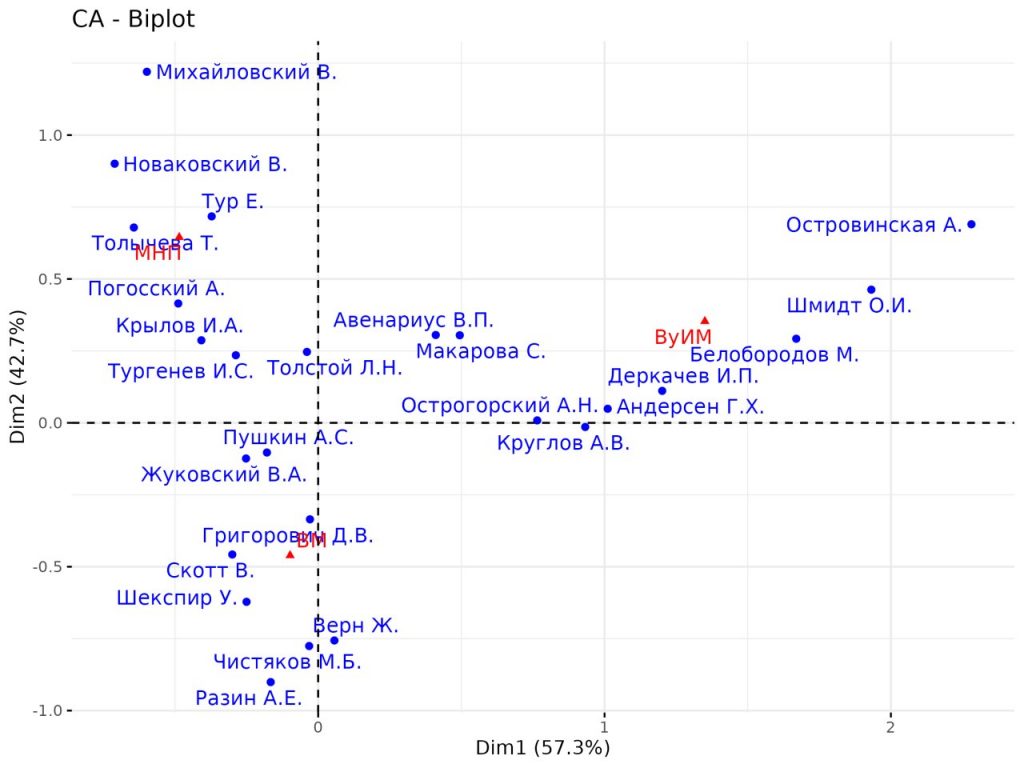
Совместный семинар Лаборатории цифровых исследований литературы и фольклора и Центра исследований детской литературы. С докладом «Как Чистяков обошел Пушкина: измерение престижа и популярности в русской критике 1860-80-х гг.» выступила аспирантка Центра исследований детской литературы Ольга Лучкина.
В докладе речь пойдет о структуре литературного канона, реконструируемого на материале критики детской литературы XIX в. Дж. Д. Портер (Stanford Literary Lab) указывает на два способа войти в литературный канон: быть прочитанным многими («популярность») и быть ценным для избранной элиты («престиж»). С помощью этих двух измерений мы рассмотрим механизмы формирования канона, чтобы объяснить место М.Б. Чистякова и А.С. Пушкина в иерархии писателей для детей. Задача доклада — прояснить не только содержание канона, но и структуру, внутренние взаимосвязи. Решить эту задачу помогают количественные методы анализа данных.
14.03.2019
На втором семинаре Лаборатории цифровых исследований литературы и фольклора с докладом » Современный метод компьютерной атрибуции текстов: надёжность, ограничения, результаты» выступил Борис Орехов НИУ ВШЭ (Москва)
Доклад посвящен широко используемому в современных исследованиях методу Delta, появившемуся в начале 2000-х годов. Его повсеместное применение обусловлено многократно проверенной надежностью, доступностью использования и простотой интерпретации результатов. Особое внимание было уделено тому, как Delta работает на русскоязычном материале, и какие традиционные вопросы атрибуции помогает решать.
Видеозапись семинара на youtube канале Пушкинского Дома https://www.youtube.com/watch?v=dctOHDggv1M
14.02.2019
Лаборатория цифровых исследований Пушкинского Дома начинает серию семинаров, посвященных современным цифровым исследованиям литературы и фольклора.
14 февраля выступил научный сотрудник Тартуского университета Артем Шеля с докладом «Изменчивое, уникальное, неповторимое»: многомерная классификация стихотворных текстов и проблема поддельности.
Аннотация:
Хранит ли форма стиха уникальный отпечаток автора? Стиховедение по-разному отвечало на этот вопрос, но демонстрировало, что различные уровни стиха способны отражать как авторскую индивидуальность, так и характерные признаки эпохи. М. И. Шапир провел многоуровневый лингвостиховедческий анализ дубиальных текстов Г. С. Батенькова, однако увеличение набора переменных не дало оснований для однозначной атетезы: исследователь получил множество противоречивых сигналов, ни один из них не мог стать решающим.
Можно ли решить «проблему противоречивых сигналов» в атрибуции при помощи многомерной статистики и машинного обучения?
В докладе пойдет речь о возможностях применения методов компьютерной стилометрии для атрибуции и атетезы коротких стихотворных текстов. Будет в частности показано, что необходимый для корректной атрибуции значительный объем текста может быть сокращен за счет увеличения количества грамматических, лексических и стиховых метрик.